Annotation
- 사전상으로는 주석의 의미이지만 Java에서는 주석 이상의 기능을 가지고 잇습니다.
- Annotation은 자바 소스 코드에 추가하여 사용할 수 있는 메타데이터의 일종입니다.
- 소스코드에 추가하면 단순 주석의 기능을 하는 것이 아니라 특별한 기능을 사용할 수 있습니다.
- 종류
- @Component
- 개발자가 생성한 Class를 Spring의 Bean으로 등록할 때 사용하는 Annotation입니다. Spring은 해당 Annotation을 보고 Spring의 Bean으로 등록합니다.
- @ComponentScan
- Spring Framework는 @Component, @Service, @Repository, @Controller, @Configuration 중 1개라도 등록된 클래스를 찾으면, Context에 bean으로 등록합니다. @ComponentScan Annotation이 있는 클래스의 하위 Bean을 등록 될 클래스들을 스캔하여 Bean으로 등록해줍니다.
- @Bean
- @Bean Annotation은 개발자가 제어가 불가능한 외부 라이브러리와 같은 것들을 Bean으로 만들 때 사용합니다.
- @Controller
- Spring에게 해당 Class가 Controller의 역할을 한다고 명시하기 위해 사용하는 Annotation입니다.
- @RequiredArgsConstructor
- Lombok으로 스프링에서 DI(의존성 주입)의 방법 중에 생성자 주입을 임의의 코드없이 자동으로 설정해주는 Annotation.
- @RequiredArgsConstructor는 초기화 되지 않은 final 필드나, @NonNull이 붙은 필드에 대해 생성자를 생성해줌
- 새로운 필드를 추가할 때 다시 생성자를 만들어서 관리해야하는 번거로움을 없애준다 (@Autowired를 사용하지 않고 의존성 주입)
- @EnableWebSecurity
- @Override
- @Transactional
- @ModelAttribute
- @Component
DAO
- DAO(Data Access Object) 는 데이터베이스의 data에 접근하기 위한 객체입니다. Database에 접근하기 위한 로직 & 비즈니스 로직을 분리하기 위해 사용합니다.
DTO
- DTO(Data Transfer Object)는 계층 간 데이터 교환을 하기 위해 사용하는 객체로, DTO는 로직을 가지지 않는 순수한 데이터 객체(getter & setter 만 가진 클래스) 입니다.
- 유저가 입력한 데이터를 DB에 넣는 과정을 보겠습니다.
- 유저가 자신의 브라우저에서 데이터를 입력하여 form에 있는 데이터를 DTO에 넣어서 전송합니다.
- 해당 DTO를 받은 서버가 DAO를 이용하여 데이터베이스로 데이터를 집어넣습니다.
VO
- VO(Value Object) 값 오브젝트로서 값을 위해 쓰입니다. read-Only 특징(사용하는 도중에 변경 불가능하며 오직 읽기만 가능)을 가집니다.
- DTO와 유사하지만 DTO는 setter를 가지고 있어 값이 변할 수 있습니다.
프레디케이트(predicate)
- 수학에서는 인수로 값을 받아 true나 false를 반환하는 함수를 프레디케이트라고 합니다.
- 자바 8에서도 Function<Apple, Boolean> 같이 코드를 구현할 수 있지만 Perdicate<Apple>을 사용하는 것이 더 표준적인 방식입니다. (또한 boolean을 Boolean으로 변환하는 과정이 없으므로 더 효율적이기도 합니다)
MSA (MicroService Architecture)
- 애플리케이션 안에 서비스들을 마이크로 서비스 단위로 쪼개어서 구성되는 것
- 마이크로서비스란, 서비스를 비즈니스 경계에 맞게 세분화 하고, 서비스 간 통신을 네트워크 호출을 통해 진행하여 확장 가능하고 회복적이며 유연한 어플리케이션을 구성하는 것
- 각각의 고유한 데이터베이스를 가지는 것으로 구성됩니다.
- 서비스가 각각 쪼개져서 운영되는 것으로 이해
NAT (Network Address Translation)
- IP 패킷의 TCP/UDP 포트 숫자와 소스 및 목적지의 IP 주소 등을 재기록하면서 라우터를 통해 네트워크 트래픽을 주고 받는 기술
미들웨어
- 미들웨어는 양 쪽을 연결하여 데이터를 주고 받을 수 있도록 중간에서 매개 역할을 하는 소프트웨어, 네트워크를 통해서 연결된 여러 개의 컴퓨터에 있는 많은 프로세스들에게 어떤 서비스를 사용할 수 있도록 연결해 주는 소프트웨어
- 통상적으로 기업에서 말하는 미들웨어 환경은 웹/어플리케이션 서버를 의미
런타임
- 프로그램이 실행되는 것에 run의 의미를 갖고 실행되는 서버 혹은 컴퓨터 내에서 프로그램이 실행이 되는 동작을 런타임
- 혹은 프로그래밍 언어가 구동 되는 환경
- ex) js를 예로 들 경우 브라우저에서 실행이 되면 런타임 환경은 브라우저가 되고, nodejs에서 실행이 된다면 런타임 환경은 nodejs가 되는 것
컨테이너
- 쉽게 말하면 애플리케이션을 환경에 구애 받지 않고 실행하는 법
- 운영체제에서 실행되는 프로세스를 격리(isolation)하여 별도의 실행 환경을 제공해주며, 해당 프로세스는 운영체제 상에서 실행되는 유일한 프로세스인 것처럼 작동하는 기술
- 즉, 운영체제에서 실행되는 여러 프로세스는 컨테이너라는 개념으로 격리되어 별도의 운영 환경을 제공해주는 기술
CI (Continuous Integration)
- CI는 지속적 통합이라는 뜻으로 개발을 진행하면서도 품질을 관리할 수 있도록 하는 것으로 여러 명이 하나의 코드에 대해서 수정을 진행해도 지속적으로 통합하면서 관리할 수 있음을 의미
- CI가 나오기 전까지는 개발을 끝마치고 배포가 되어야만 코드에 오류는 없는지, 올바르게 동작하는지를 검증하며 코드 품질을 관리할 수 있었습니다.
- CI를 적용하게 되면 각자의 개발자가 자신의 구현해야 할 기능을 구현하면 됨
- 이후 완성이 되면 main 브랜치와 통합하고 코드가 잘 빌드되는지 보고, 올바르게 동작하는지 테스트하며 코드에 버그가 있다면 해결
- 하지만 개발자가 직접 코드를 병합하고 빌드, 테스트를 검증하는 것은 시간이 많이 소요될 뿐만 아니라 귀찮고 그 양도 프로젝트의 크기가 커질수록 많아질 수밖에 없었습니다.
- 이를 자동화하면 개발자가 빌드와 테스트를 직접 하지 않고도 수정한 코드를 브랜치에 병합하기만 하면 자동으로 빌드와 테스트를 검증할 수 있습니다.
- 개발자가 단위별로 구현한 부분을 병합할 때마다 자동화된 빌드와 테스트가 트리거되어 실행됨
- 결과를 통해 우리는 어떤 부분에서 문제가 있는지 배포 전에 확인할 수 있고 배포가 완성된 후에야 버그를 수정할 수 있던 기존의 문제를 빠르고 정확하게 해결 가능
- 간단한 순서
- 개발자가 구현한 코드를 기존 코드와 병합
- 병합된 코드가 올바르게 동작하고 빌드되는지 검증
- 테스트 결과 문제가 있다면 수정하고 다시 1로 돌아갑니다.
- 문제가 없다면 배포를 진행
CD (Continuous Deployment)
- CD는 지속적 배포로 소프트웨어가 항상 신뢰 가능한 수준에서 배포될 수 있도록 관리하자는 개념으로 지속적 제공으로 사용되기도 합니다.
- 지속적 제공은 CI를 통해서 새로운 소스코드의 빌드와 테스트 병합까지 성공적으로 진행되었다면, 빌드와 테스트를 거쳐 github과 같은 저장소에 업로드하는 것을 의미
- 지속적 배포는 이렇게 성공적으로 병합된 내역을 저장소뿐만 아니라 사용자가 사용할 수 있는 배포환경까지 릴리즈하는 것을 의미
- 지속적 배포에서는 지속적 통합을 통해 빌드한 소스코드를 테스트 가능한 알파나 베타 버전으로 만듬
- 이 버전에서 테스트를 수행해 문제가 발생하면 수정한 뒤 정식 버전으로 배포
- 대표적으로 Jenkins, Travis가 있습니다.
Pub-Sub

- 이벤트(메시지)를 발행하는 Publisher가 존재하며, Publisher는 특정 Channel(혹은 Topic)에 이벤트 전송
- 특정 Channel(혹은 Topic)을 구독하는 Subscriber가 존재하며, Publisher에 관계없이 발행된 이벤트를 받을 수 있습니다.
Kafka

- Kafka에서는 Producer/Consumer라는 개념이 등장하는데 각각 Publisher/Subscriber와 그 기능이 동일
- Producer는 Topic에 이벤트를 보내고, 이 이벤트는 Topic의 각 Partition에 분산되어 저장
- Topic을 구독하고 있는 Consumer group 내의 Consumer는 각각 1개 이상의 Partition으로부터 이벤트를 가져옵니다.
- 만약 partition 개수보다 consumer 개수가 많다면 아무 일도 하지 않는 consumer가 생기기 때문에 항상 partition 수를 consumer보다 같거나 크게 해주는 것이 좋습니다.
Redis
- Redis에는 그룹이라는 개념이 존재하지 않고, 각 subscriber가 channel을 구독하고 있습니다.
- 이 때 중요한 점은, channel은 이벤트를 저장하지 않는다는 것
- 만인 Channel에 이벤트가 도착했을 때 해당 채널의 subscriber가 존재하지 않는다면 이벤트는 사라집니다.
Kafka vs Redis
- 이벤트의 저장 여부
- Kafka는 발행된 이벤트가 각 Partition에 저장됨. 하지만 Redis는 발행된 이벤트를 저장하지 않기 때문에 구독자가 없다면 해당 이벤트는 사라지고 맙니다.
- 이벤트의 구독과 발행이 실시간으로 이루어져야 되는 상황인지, 혹은 언제든 발행된 이벤트를 읽으면 되는 상황인지에 따라 선택이 달라집니다.
- 메시지가 생성되었을 대 실시간 처리를 위해 Redis나 Memcached를 사용할 수 있습니다.
- 그러나 데이터를 메모리에 저장하기 때문에 장기간 보관하기에 불안정
- expired time이 지정되어 있지 않은 경우 메모리가 꽉 차면 문제가 생길 수 있습니다.
- 한 이벤트를 받을 수 있는 Subscriber(Consumer) 개수
- 한 API에 대해 Scale-out 등의 이유로, 여러 서버가 작동될 수도 있음
- Coupon 서비스는 유저 회원 가입에 대한 Topic을 구독하고 있고 유저가 회원가입 햇다는 이벤트를 받으면 회원가입 기념 쿠폰을 발행합니다.
- 그리고 이때 Coupon 서비스에 대해 2개의 서버를 사용한다고 하고

만약 Kafka를 사용한다면 Consumer의 수와 관계없이 유저 회원가입당 하나의 쿠폰이 발행될 것입니다.
하지만 Redis를 사용한다면?
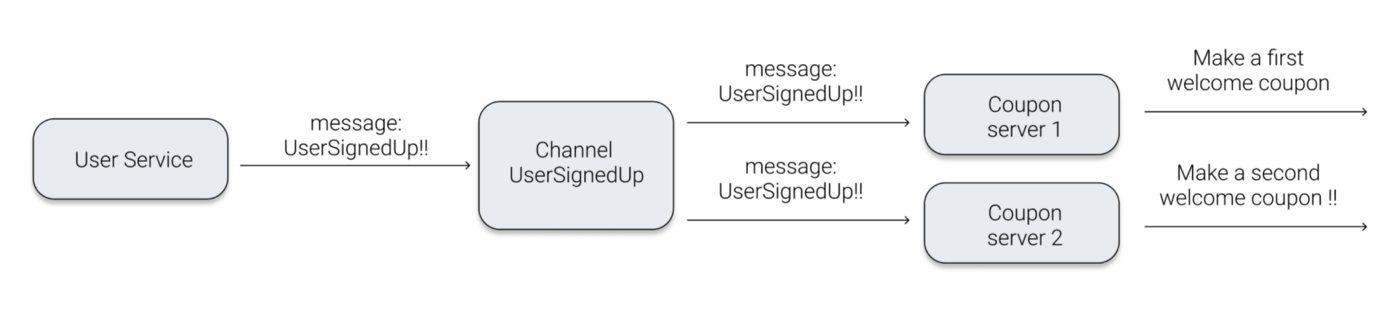
유저는 한 번의 회원가입으로 두 개의 쿠폰을 얻게 됩니다.
즉, 한 이벤트에 대해 한 번의 기능만 작동되어야 한다면 Kafka를 사용하는 것이 유리
반대로 여러 서버에 모두 갱신되어야 할 데이터를 보내는 상황에서는 Redis를 사용하는 것이 적합할 것입니다.
물론 Kafka에서도 각 Process마다 다른 group Id를 부여하여 사용할 수도 있습니다.
ORM (Objective Relational Mapping)
- 객체와 관계형 데이터베이스의 데이터를 자동으로 Mapping(연결) 해주는 Framework
- 객체지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용하기 때문에 객체 모델과 관계형 모델간에 불일치가 존재
- ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결
- 즉, 객체를 통해 간접적으로 데이터베이스 데이터를 다룸
- 장점
- 객체지향적인 코드로 인해 더 직관적이고 로직에 집중할 수 있다
- SQL문이 아닌 클래스의 메서드를 통해 데이터베이스를 조작할 수 있으므로 개발자가 객체 모델만 이용해서 프로그래밍을 하는 데 집중할 수 있습니다.
- 선언문, 할당, 종료 같은 부수적인 코드가 없거나 줄어듭니다.
- 객체마다 코드를 별도로 작성하기 때문에 코드의 가독성이 높아집니다.
- SQL의 절차적이고 순차적인 접근이 아닌 객체지향적인 접근으로 인해 생산성을 높여줍니다.
- 재사용 및 유지보수의 편리성이 증가한다
- ORM은 독립적으로 작성되어 있고, 해당 객체들을 재활용할 수 있습니다.
- 매핑 정보가 명확하여 ERD를 보는 것에 대한 의존도를 낮출 수 있습니다.
- DBMS에 대한 종속성이 줄어든다
- 대부분 ORM 솔루션은 DB에 종속적이지 않기 때문에 구현 방법뿐만 아니라 많은 솔루션에서 자료형 타입까지 유효하다 (*종속성? 프로그램 구조가 데이터 구조에 영향을 받는다)
- 프로그래머는 Object에 집중함으로 극단적으로 DBMS를 교체하는 거대한 작업에도 비교적 적은 리스크와 시간이 소요됩니다.
- 또한 자바에서 가공할 경우 equals, hashCode의 오버라이드 같은 자바의 기능을 이용할 수 있고, 간결하고 빠른 가공이 가능합니다.
- 객체지향적인 코드로 인해 더 직관적이고 로직에 집중할 수 있다
- 단점
- 완벽한 ORM 으로만 서비스를 구현하기가 어렵다
- 사용하기는 편하지만 설계는 매우 신중하게 해야합니다.
- 프로젝트의 복잡성이 커질경우 난이도 또한 올라갈 수 있습니다.
- 잘못 구현된 경우에 속도 저하 및 심각할 경우 일관성이 무너지는 문제점이 생길 수 있습니다.
- 일부 자주 사용되는 대형 쿼리는 속도를 위해 SP를 쓰는 등 별도의 튜닝이 필요한 경우가 있습니다.
- DBMS의 고유 기능을 이용하기 어렵다 (단점으로만 볼 수 없다 → 특정 DBMS의 고유기능을 이용하면 이식성이 저하된다)
- 프로시저가 많은 시스템에서 ORM의 객체 지향적인 장점을 활용하기 어렵습니다.
- 이미 프로시저가 많은 시스템에선 다시 객체로 바꿔야하며 그 과정에서 생산성 저하나 리스크가 많이 발생할 수 있습니다.
- 완벽한 ORM 으로만 서비스를 구현하기가 어렵다
Redis
https://jmdwlee.tistory.com/22
Race Condition
- 2개 이상의 프로세스가 공통 자원을 병행적으로(concurrently) 읽거나 쓰는 동작을 할 때, 공용 데이터에 대한 접근이 어떤 순서에 따라 이루어졌는지에 따라 그 실행 결과가 같지 않고 달라지는 상황을 말함
- 간단히 말하면 경쟁하는 상태, 즉 두 개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황
샤딩
- 샤딩(Sharding)을 알기전 우선 샤드의 사전적 의미를 보면 조각 또는 파편을 의미한다. 즉, 데이터베이스에서의 샤딩(Sharding)은 한 테이블의 row들을 여러 개의 서로 다른 테이블, 즉 파티션으로 물리적으로 분리하는 것이다. row들을 여러 개의 서로 다른 테이블로 분해하는 것이기 때문에 한 테이블을 Horizontal Partitioning 했다고 볼 수 있다.
CORS
GCM
FCM
메모리 단편화
JPA
JSP
Base64
- Base64란 8비트 이진 데이터(예를 들어 실행 파일이나, ZIP 파일 등)를 문자 코드에 영향을 받지 않는 공통 ASCII 영역의 문자들로만 이루어진 일련의 문자열로 바꾸는 인코딩 방식을 가리키는 개념
- Base64는 어떤 문자와 기호를 쓰느냐에 따라 다양한 변종이 있지만, 대부분 처음 62개는 알파벳 A-Z, a-z와 0-9를 사용하며 마지막 두 개를 어떤 기호를 쓰느냐의 차이만 있음
- Base64를 사용하는 이유?
- Base64로 인코딩을 하게 되면 6bit당 2bit의 Overhead가 발생하여 전송해야 될 데이터의 크기가 양 33% 정도 늘어남
- 33%나 데이터의 크기가 증가하고, 인코딩과 디코딩의 추가 연산까지 필요한데 사용하는 이유는?
- 통신과정에서 바이너리 데이터의 손실을 막기 위해 사용 → 플랫폼 독립적으로 Binary Data(이미지나 오디오)를 전송할 필요가 있을 때, ASCII로 Encoding 하여 전송하게 되면 여러 가지 문제가 발생할 수 있음
- ex) ASCII는 7 bits Encoding인데 나머지 1bit를 처리하는 방식이 시스템 별로 상이
- 일부 제어 문자(Line ending)의 경우 시스템 별로 다른 코드값을 가짐
- 위와 같은 문제로 ASCII는 시스템 간 데이터를 전달하기에 안전하지 않음
- Base64는 ASCII 중 제어 문자와 일부 특수문자를 제외한 64개의 안전한 출력 문자만 사용
- 즉, Base64는 HTML 또는 Email과 같이 문자를 위한 Media에 Binary Data를 포함해야 될 필요가 있을 때, 포함된 Binary Data가 시스템 독립적으로 동일하게 전송 또는 저장되는 걸 보장하기 위해 사용
Spring Rest docs
Querydsl
Proxy
AOP
- AOP가 필요한 상황
- 모든 메소드의 호출 시간을 측정하고 싶다면?
- 공통 관심 사항(cross-cutting concern) vs 핵심 관심 사항(core concern)
- 회원 가입 시간, 회원 조회 시간을 측정하고 싶다면?
Spring DDL auto
Stream()
->
ResponseEntity
UUID (Universally Unique IDentifier)
- 네트워크 상에서 고유성이 보장되는 id를 만들기 위한 표준 규약
- UUID는 128비트의 숫자이며, 32자리의 16진수로 표현
이름 길이 (바이트) 길이 (16진수 숫자) 내용 time_low 4 8 시간의 low 32비트를 부여하는 정수 time_mid 2 4 시간의 middle 16비트를 부여하는 정수 time_hi_and_version 2 4 최상위 비트에서 4비트 "version", 그리고 시간의 high 12비트 clock_seq_hi_and_res clock_seq_low 2 4 최상위 비트에서 1-3비트, 그리고 13-15비트 클럭 시퀀스 node 6 12 48비트 노드 id - UUID는 1,3,4,5 버전이 있고 이 중 가장 많이 쓰이는 버전은 1,4
- 1: 타임스탬프를 기준으로 생성(호스트 ID, 시퀀스 번호 및 현재 시각으로 UUID 발급)
- 4: 랜덤 생성(무작위 UUID 생성) → randomUUID
MIME (Multipurpose Internet Mail Extensions)
NPE (Null Point Exception)
Yarn
MultipartFile
NotNull, NotBlank,
프로덕션
N+1 문제
Feign
'개발 Tip' 카테고리의 다른 글
| [개발] 테스트 코드란? (0) | 2023.06.26 |
|---|---|
| [Tip] 패키지 구조는 어떻게 짜는 게 맞을까? (0) | 2023.01.15 |